Current brief
LLM comparison
A trust-first read on where OpenAI, Anthropic, and Gemini each fit best after Claude Opus 4.8 and Gemini 3.5 Flash.
Brief summary
OpenAI is still the broadest default for teams that want one vendor across chat, coding, search, computer use, and execution, and GPT-5.5 materially strengthens that case. Claude Opus 4.8 is now the sharpest public trust signal for code-heavy agents, careful review, document reasoning, computer use, long context, and long-running workflows. Gemini is most compelling when long context, Google ecosystem leverage, search grounding, multimodality, and cost discipline matter more than mindshare.
The current caveat is simple: Gemini 3.5 Flash is public, but Gemini 3.5 Pro is not yet broadly released. Claude Mythos Preview is also not generally available. Trust-oriented buyers should keep both on the roadmap, but not treat either as a production default until access, pricing, model IDs, and comparable public benchmark data exist.
Why this comparison belongs here
Trust in AI platforms is not just about intelligence. It is about cost profile, operating consistency, context handling, migration burden, safety posture, and whether leadership changes across model generations feel stable or chaotic.
The current OpenAI, Anthropic, and Google releases all change the trust read. GPT-5.5 raises OpenAI's ceiling for terminal work, computer use, knowledge work, and long-context tasks while increasing flagship API pricing. Claude Opus 4.8 keeps regular Opus pricing, adds stronger coding and agent behavior, introduces faster fast-mode execution at a premium, and gives Anthropic a more compelling public benchmark story. Gemini 3.5 Flash raises Google's floor for fast agentic workloads, while Gemini 3.5 Pro remains an unpublished promise.
What the current frontier snapshot says
The newest official benchmark and pricing sources sketch a fairly crisp division of labor.
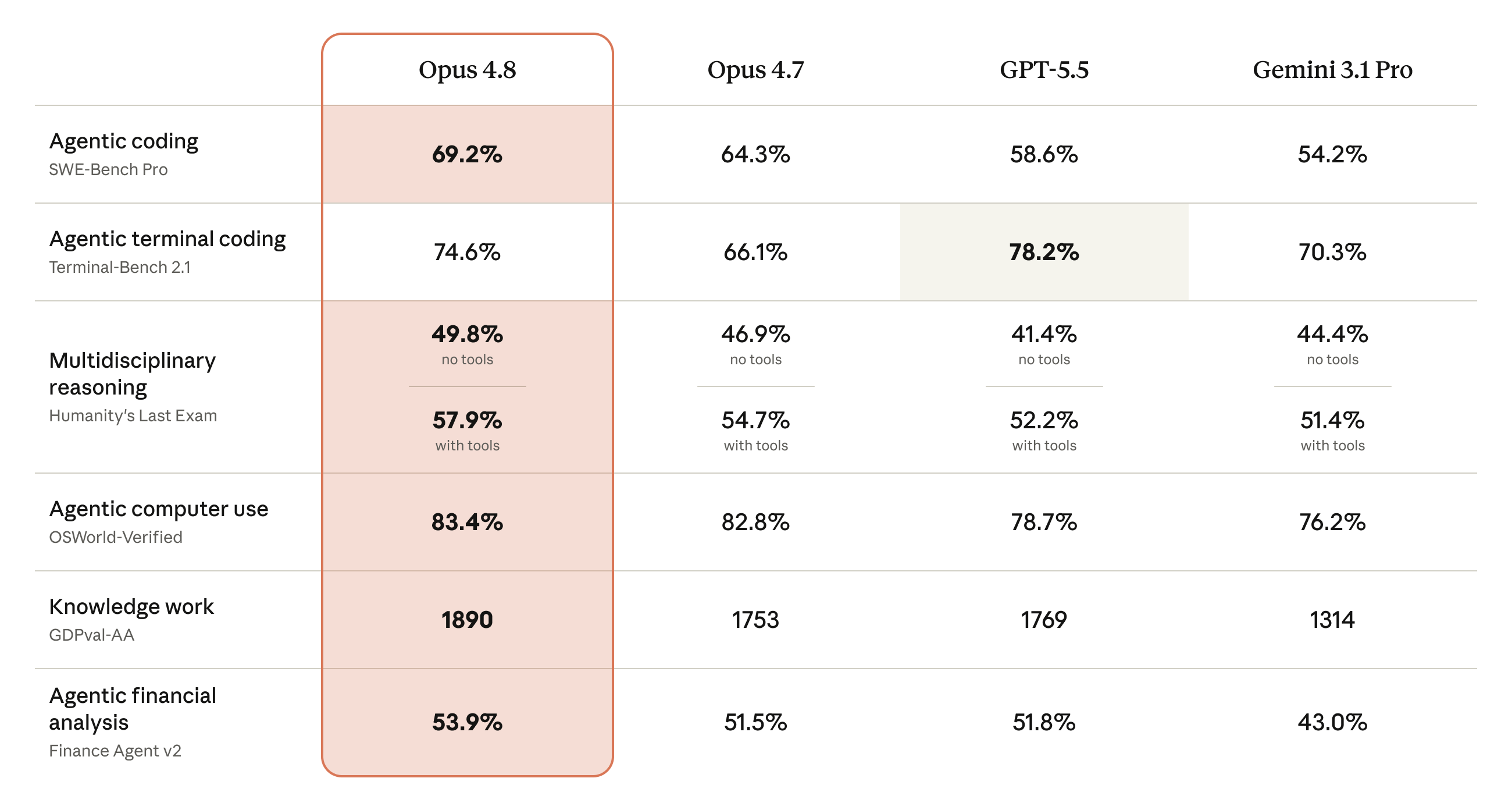
- Claude Opus 4.8 gives Anthropic the stronger public SWE-bench Pro, OSWorld-Verified, GDPval-AA, long-context GraphWalks, and MCP Atlas story among generally available Claude models.
- GPT-5.5 still gives OpenAI a strong terminal-agent and broad-platform signal, especially when product surface, tools, search, and general rollout matter.
- Gemini 3.5 Flash makes Google's public model line more serious for agentic work than older Flash assumptions suggested, especially on MCP Atlas and Finance Agent v2.
- Gemini 3.5 Pro and Claude Mythos Preview should be described as unpublished or gated until general access and comparable public benchmark tables exist.
- All three public ecosystems are close enough that real workflow tests matter more than leaderboard rankings.
Current benchmark read after Claude Opus 4.8
The trust question is not which logo wins. It is whether the model is predictably strong in the exact operating mode you will ship.
| Area | Best current signal | Trust implication |
|---|---|---|
| Agentic coding | Opus 4.8 posts 69.2% on SWE-bench Pro and 88.6% on SWE-bench Verified. GPT-5.5 posts 58.6% on SWE-bench Pro in Anthropic's comparison table. | Claude is currently the cleaner public code-repair bet, but teams should still run local repo evals because benchmark harnesses do not capture every codebase convention. |
| Terminal coding | GPT-5.5 posts 78.2% on Terminal-Bench 2.1 in Anthropic's table, ahead of Opus 4.8 at 74.6% and Gemini 3.1 Pro at 70.3%. Google reports Gemini 3.5 Flash at 76.2%. | OpenAI deserves first evaluation for CLI-heavy developer agents, with Claude and Gemini close enough to test when their broader ecosystem fit is better. |
| Professional work | Opus 4.8 posts 1890 Elo on GDPval-AA, ahead of GPT-5.5 at 1769, Opus 4.7 at 1753, and Gemini 3.1 Pro at 1314 in Anthropic's table. | Claude has the strongest current public all-around professional-work signal in this comparison, but GDPval score formats differ across reports. |
| Financial research | Gemini 3.5 Flash posts 57.9% on Finance Agent v2, ahead of Opus 4.8 at 53.9%, GPT-5.5 at 51.8%, and Opus 4.7 at 51.5%. | Google deserves real evaluation for SEC-filing and financial-research workflows even if Claude remains stronger on code and computer use. |
| Document and visual reasoning | Opus 4.8 improves over Opus 4.7 on OfficeQA and OfficeQA Pro under Anthropic's internal agentic harness, and posts 83.4% on OSWorld-Verified. | Trust-sensitive document work should be tested on the buyer's own files. Vendor tables disagree enough that local evaluation matters more than a headline score. |
| Tool orchestration | MCP Atlas puts Gemini 3.5 Flash at 83.6%, Opus 4.8 at 82.2%, Opus 4.7 at 79.1%, Gemini 3.1 Pro at 78.2%, and GPT-5.5 at 75.3%. | Tool-use routing should stay empirical. Google and Anthropic are both strong enough that your actual tools, failure modes, and permission model should decide. |
| Graduate-level reasoning | GPQA Diamond is tightly clustered: Gemini 3.1 Pro at 94.3%, Opus 4.7 at 94.2%, and Opus 4.8 at 93.6% in Anthropic's table. | At the frontier, differences can be too small to dominate procurement. Governance, latency, tooling, data paths, and review burden decide the safer choice. |
Cost belongs in the benchmark
A trust comparison should not stop at score tables. Total task cost is part of reliability because it determines whether teams can afford enough retries, review, monitoring, and fallback routing.
| Cost input | What to record | Trust implication |
|---|---|---|
| Token mix | Input tokens, cached input tokens, visible output tokens, and billed reasoning tokens per task or benchmark attempt. | A high-scoring model can be the wrong default if it spends far more total tokens than a cheaper near-peer. |
| Tool costs | Search calls, code execution, file search, MCP calls, browser actions, and provider-side tool fees. | Tool-heavy agents can look cheap in model pricing and expensive on the actual invoice. |
| Failure cost | Retries, partial completions, failed-run billing, and human review minutes. | Trust is not just first-pass accuracy. It is the cost of getting to an approved answer. |
| Context pricing | Long-context surcharges, cache-hit rates, batch discounts, and output caps. | Large context windows are only useful when the model remains accurate and the price curve is sustainable. |
Why older generations still matter
Model selection is not static, and earlier generations shape buyer trust more than one benchmark cycle does.
- OpenAI built its advantage on broad adoption and all-rounder utility.
- Anthropic built trust through coding strength, long-context reliability, and a more organic assistant feel for many users.
- Google's Gemini line kept closing gaps while leveraging massive context windows, multimodality, and ecosystem reach.
- A release that changes model IDs, effort settings, output behavior, or pricing should be treated as a migration event, not just a better score.
Creative writing is a revealing trust test
Creative writing still matters because it exposes tone, judgment, and overfitting to style prompts. But for an enterprise trust report, it should sit below operational evidence: code execution quality, document reasoning, tool use, computer use, latency, token behavior, and whether the migration path creates production risk.
A trust-oriented buyer should therefore ask not 'which model wins?' but 'which failure mode can I live with?' Generic output, tool underuse, scope drift, price premium, browsing weakness, token changes, or context tradeoffs each matter differently by workload.
No single public model dominates. GPT-5.5 strengthens OpenAI's broad platform case. Claude Opus 4.8 strengthens Anthropic's case for high-trust coding, agent review, documents, and long-running work. Gemini 3.5 Flash strengthens Google's fast-agent and tool-use story, while Gemini 3.5 Pro is still unpublished.
Current provider benchmark tables and model docs
Reference shelf
A short set of current references behind the trust lens: model benchmarks, platform pricing, ecosystem docs, and implementation architecture.
Primary release source for Opus 4.8, including its benchmark table, price continuity, fast mode, and current premium Claude positioning.
Primary source for the detailed Opus 4.8 benchmark, safety, agent, professional-work, and long-context evaluations.

Primary current source for OpenAI's GPT-5.5 benchmark table, agentic coding, computer-use, knowledge-work, pricing, and safety positioning.
Useful for evaluating the broader OpenAI platform surface, tool pricing, and current flagship model economics.

Primary Google source for Gemini 3.5 Flash and the current public status of Gemini 3.5 Pro.

Adjacent systems reference on why enterprise AI reliability depends on data flow, policy controls, logging, model access, and workflow design.